Projects
Ongoing Projects
Mapping German fiction in translation in the German National Library catalogue (1980-2020)
This project is dedicated to making translations visible and disentangling the roles of the author, place of publication, and language in carving the paths that German fiction travels in the world of literature. These channels of transfer are documented in archives of national literatures and this project presents an unprecedented study of translated German fiction by sourcing bibliographic data of translations from the German National Library. It is a first attempt at utilizing the wealth of data openly accessible through the library catalogue and at designing, exploring, and testing a quantitative model of analysis for German fiction in translation, drawing on social network analysis, descriptive statistics, and geomapping. By analyzing the role certain languages and authors play in the field of translation, this thesis investigates which works of fiction and authors are overrepresented and which ones are marginal in the translation network. This thesis builds on the notion of translationalism—that certain authors set themselves apart by connecting several linguistic communities in geographic space—as a driving force behind the literary transfer of translations. Translationalism, as argued here, invites the reader to re-evaluate what is categorized as world literature by drawing attention to the role of the national canon and the national collection in the global circulation of German fiction in translation.
For scripts and the thesis appendix consult the Github repository.
Read my thesis here.
Geomapping bibliographic Translation data from the German National Library Catalogue: A Casestudy
Prototype for visualizing bibliographic data for translations extracted from the German National Library catalogue in geographic space in Shinyapp. This work has been presented as a poster at the Spatial Humanities Conference in Ghent in 2022.
Code and script Dataverse
Past Projects
Cultural Crosscurrents Catalogue of Translations in Stuart and Commonwealth Britain (1641-1660)
Currently featuring over 1700 entries, the Cultural Crosscurrents Catalogue is an online catalogue that gathers bibliographic data on translations in all and into all languages printed in England, Scotland, Ireland, and ‘New England’, or translations printed abroad but in English, for the two decades covering the English Civil Wars and the Interregnum.
As part of a postdoc at the Université de Montréal, I helped evaluate and improve the FAIRness of the CCC. I also created data visualizations (geographic maps and language networks).
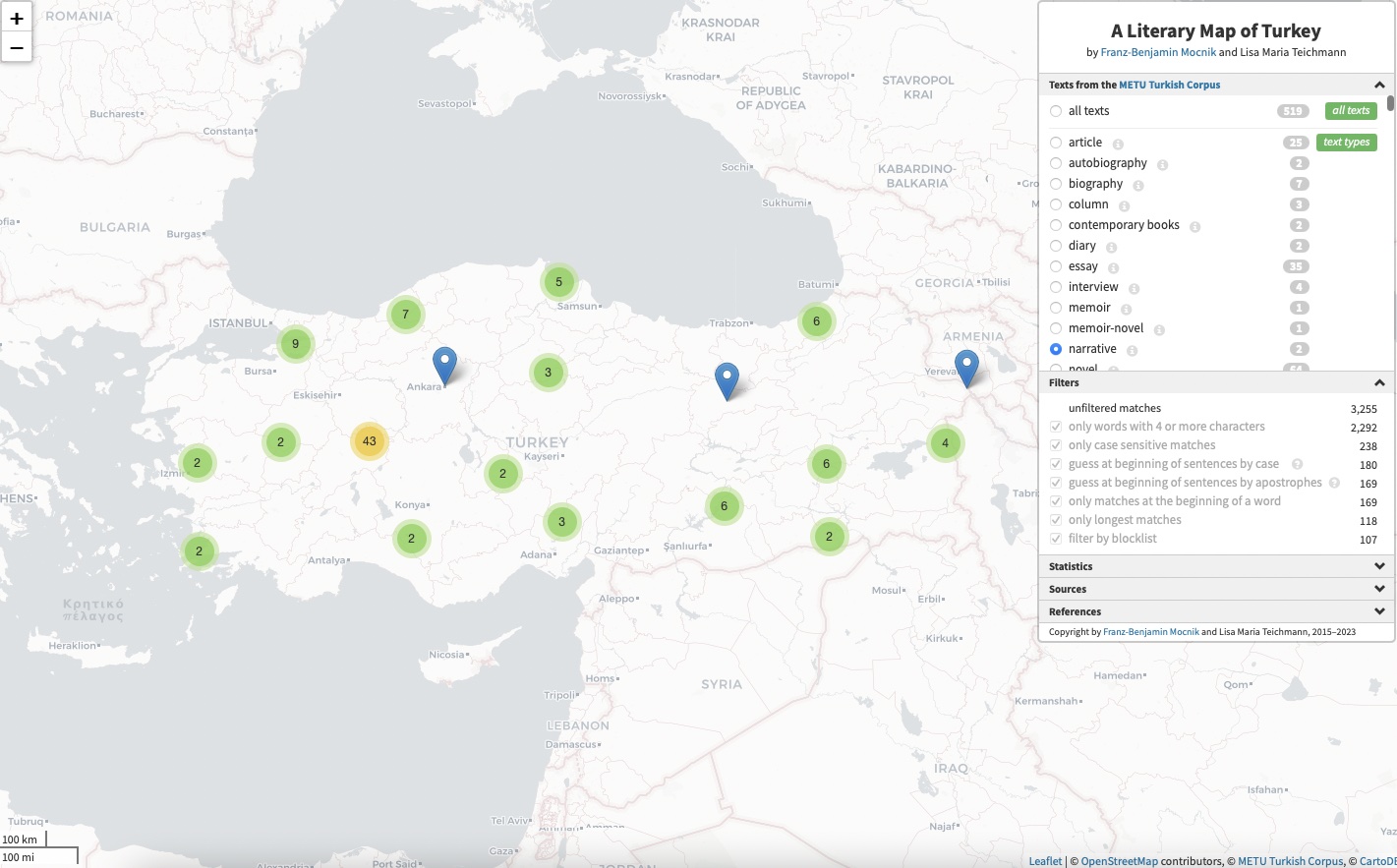
A Literary Atlas of Turkey
An interactive map for toponyms extracted from the METU Turkish corpus (co-authored with Franz-Benjamin Mocnik)
Romans à lire: données bibliographiques de BANQ
Co-autrice avec Pascale Brissette et Julien Valliéres
Description de la base de données Romans à lire, une ressource de Bibliothèque et Archives nationales du Québec (BANQ). Cette base de données peut être consultée à travers l’interface web disponible sur le site de BANQ, mais on ne trouve sur ce site aucune information sur la genèse et les paramètres de la base. La description que nous en proposons vise à combler cette lacune et à permettre son utilisation en contexte de recherche; elle est issue, d’une part, d’informations obtenues auprès de la direction de BANQ, d’autre part d’analyses statistiques menées à partir d’une copie de la base remise aux auteurs le 23 janvier 2023. BANQ interdit le partage de cette copie et nous ne pouvons donc la rendre publique; cependant, la base elle-même peut toujours être consultée en ligne. Cette collection documentaire contient une note de recherche au titre éponyme, des tables de données, des diagrammes et des scripts R. Les statistiques fournies dans la note de recherche, les scripts R qui ont servi à produire ces statistiques ainsi que les diagrammes peuvent être reproduits et utilisés librement.
Dataverse pour Rapport et statistiques descriptives